📖 Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index
Hao Xu1, Jiacheng Liu1,2, Yejin Choi3, Noah A. Smith1,2, Hannaneh Hajishirzi1,2
1University of Washington, 2Allen Institute for AI, 3Stanford University
[Web Interface] [API Endpoint] [Docs] [Code] [Paper] [Benchmark Contamination Bulletin]
Curious about what’s inside Internet-scale corpora? You’re in the right place 🤩!
We make several open text corpora searchable: {Common Crawl 2025 Janurary-July crawls, DCLM-baseline, and Pile}. In total, these encompass 83 TB of text, which is the largest body of searchable text in the open-source community (as of September 2025).
Infini-gram mini is an efficient search engine designed to handle exact-match search on arbitrarily long queries across Internet-scale corpora with small storage overhead. The index takes only 44% as much storage as the text it indexes (7% of storage requirement of the OG infini-gram).
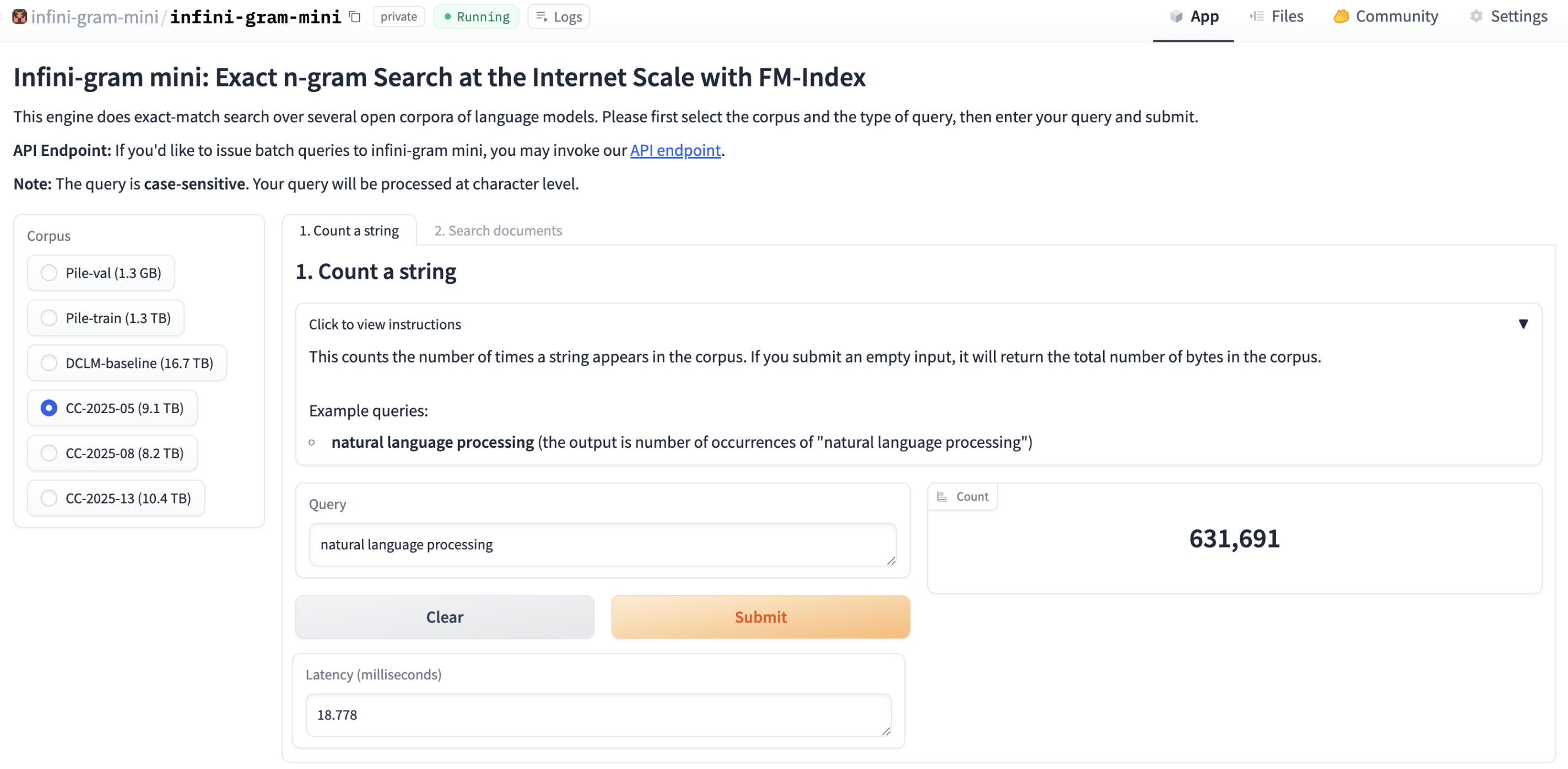
Infini-gram mini can count the exact number of matches for a given string in under a second on CC 2025 January crawl (9.1 TB).
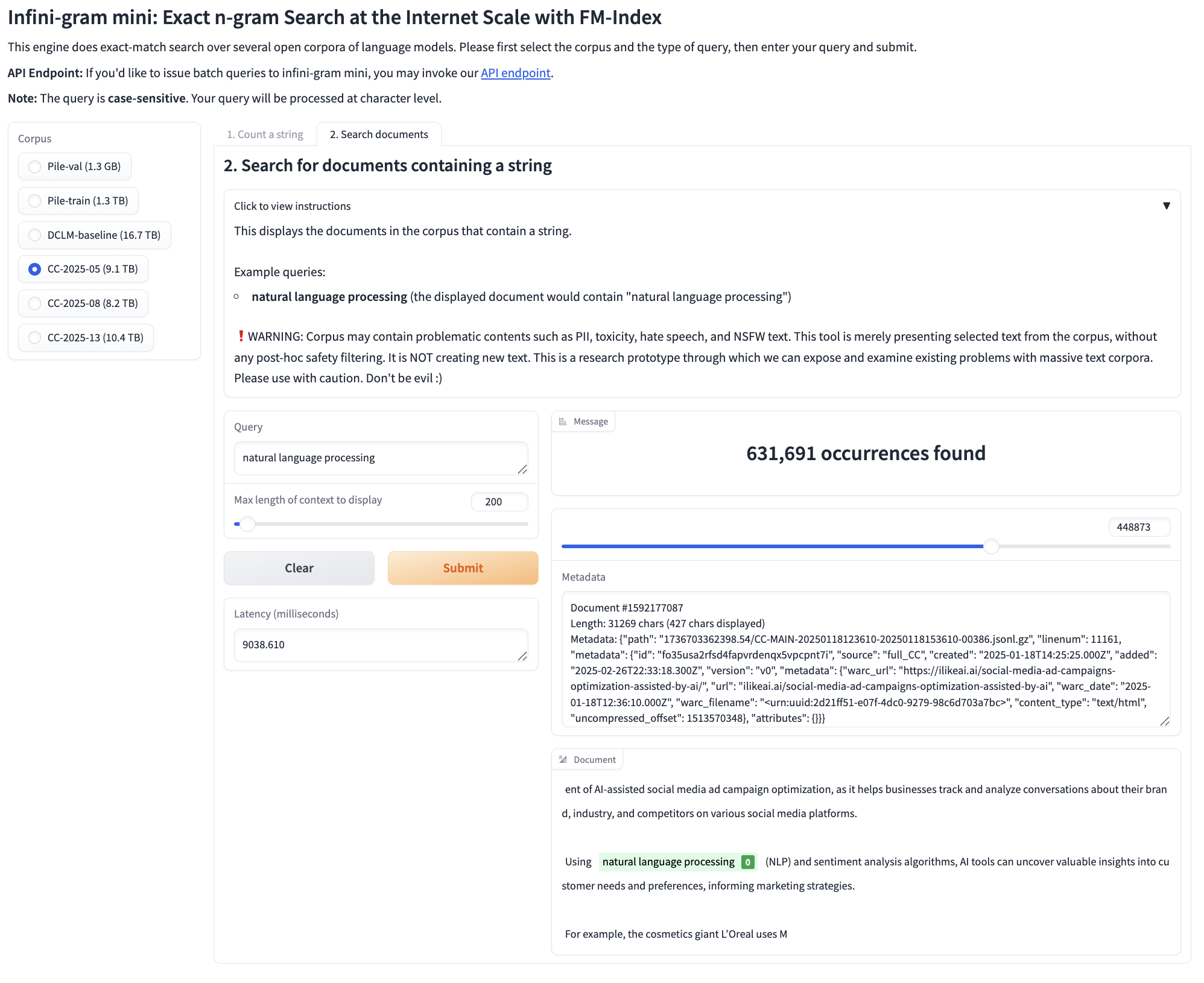
Beyond counting, Infini-gram mini can also retrieve the original documents containing your query string along with metadata.
How can I use infini-gram mini?
Depending on your use case and needs, there are several options:
- If you’d like to explore infini-gram mini or use in small volume, please check out our web interface.
- If you’d like to programmatically query infini-gram mini, we offer a free and easy-to-use API endpoint, please check out the API documentation.
- If you’d like to custimize the indexing or the inference engine, we release our source code.
What can I use infini-gram mini for?
In our paper, we use infini-gram mini to analyze benchmark contamination at large scale.
Infini-gram mini has more potential use cases, such as
- Data curation
- Task-specific dataset construction
… and more!
Below we show a few results from our paper, which uses infini-gram mini for benchmark contamination detection.
Analyzing benchmark contamination
Using infini-gram mini, we can easily detect lexical overlap between benchmark entries and text corpus, thus finding contaminated benchmark entries. We find several core LM evaluation benchmarks to be heavily contaminated in Internet crawls (e.g., 74.2% in GSM8K and 40.0% in AIME-2024), which could lead to overestimating the capabilities of language models if trained on such data.
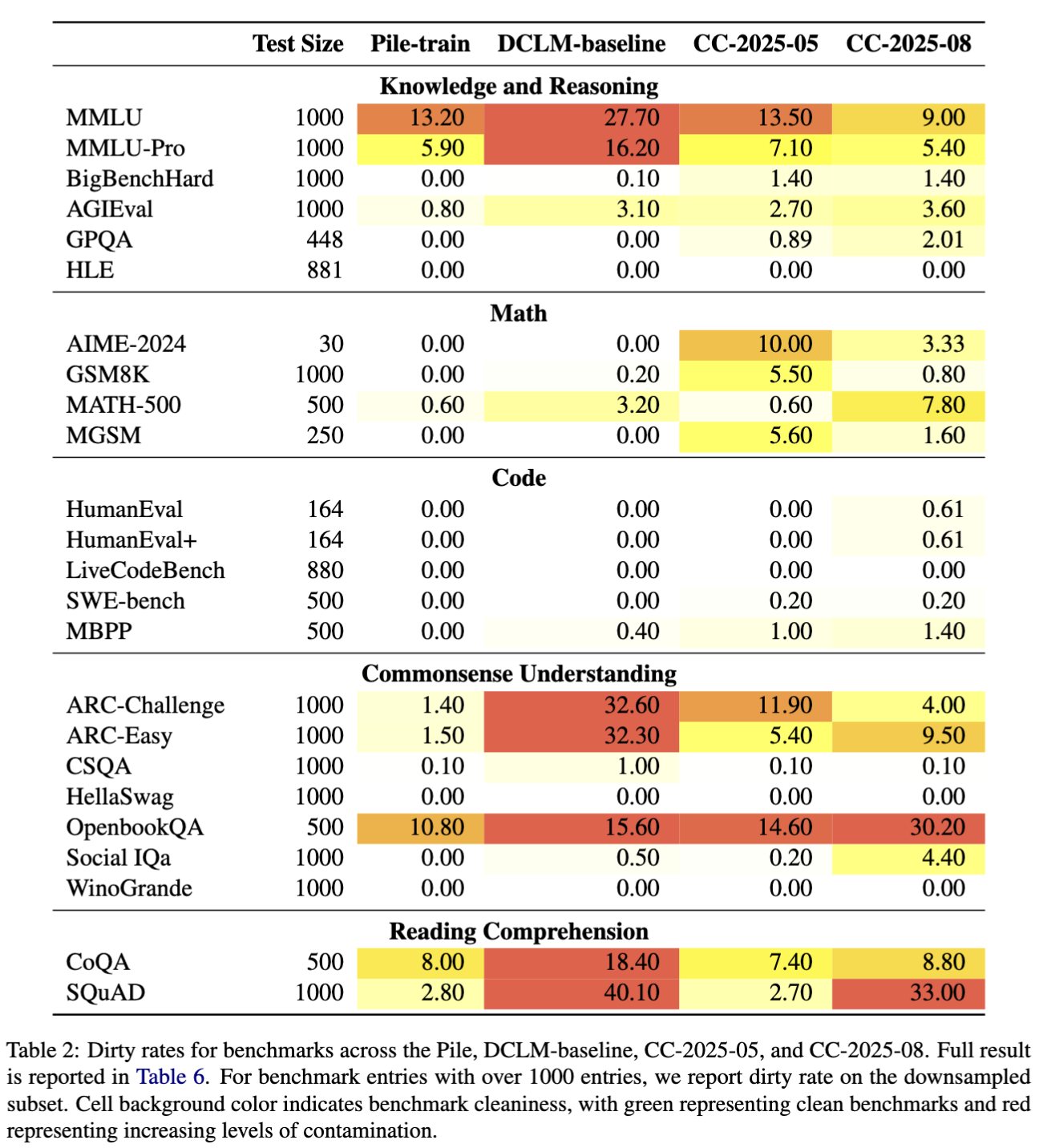
We host a benchmark contamination bulletin to share the contamination rate of many core and community-contributed benchmarks.
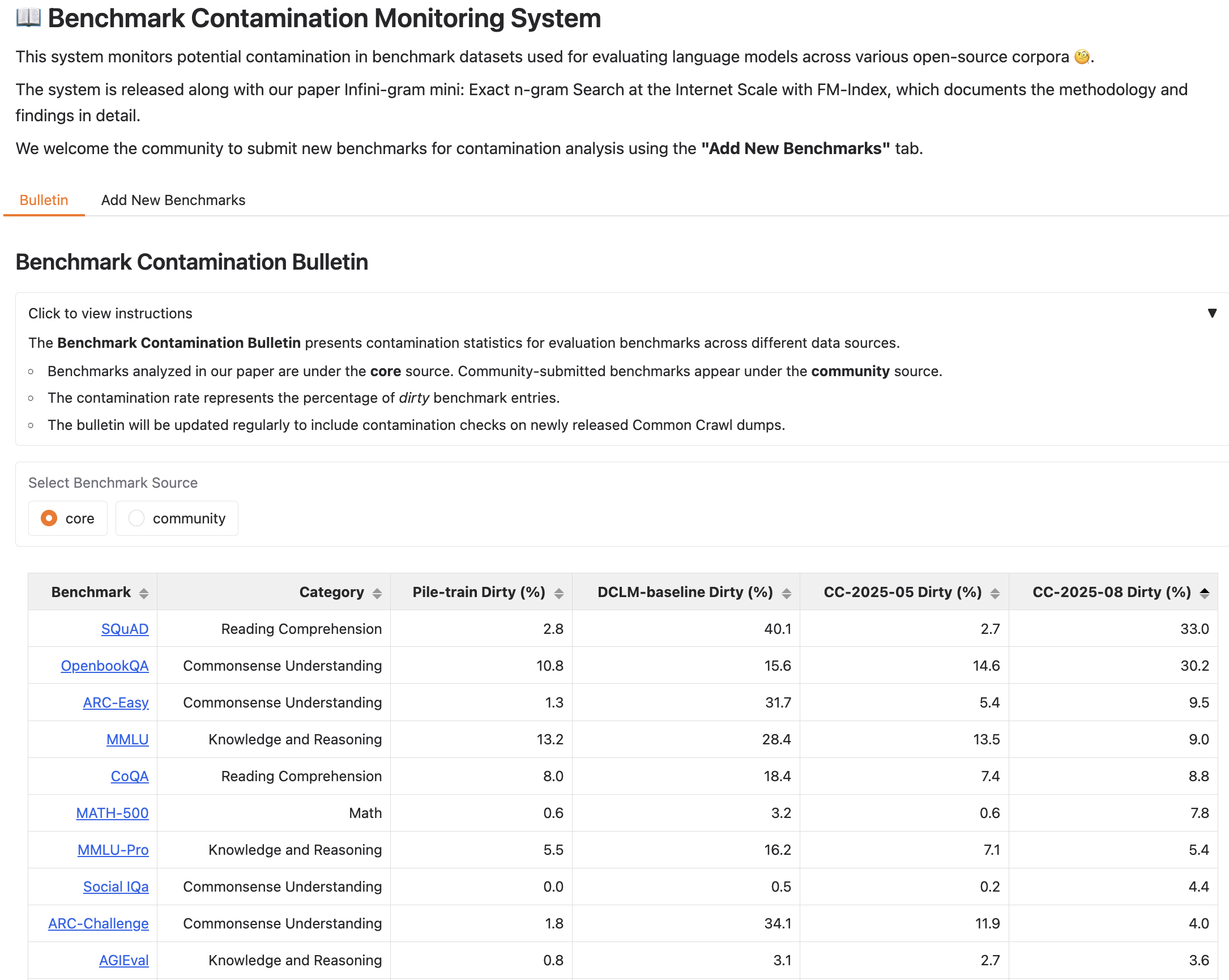
We also welcome the community to upload their own benchmarks for contamination check.
Behind infini-gram mini engine
The infini-gram mini index is a “FM-index”, a compact data structure frequently used in bioinformatics but not yet used for natural language data at scale.
It stores a compact variation of a suffix array and the text corpus, greatly reducing storage overhead to 0.44x (theoretically can be as small as 0.26x).
Here is an illustration of the data structure:
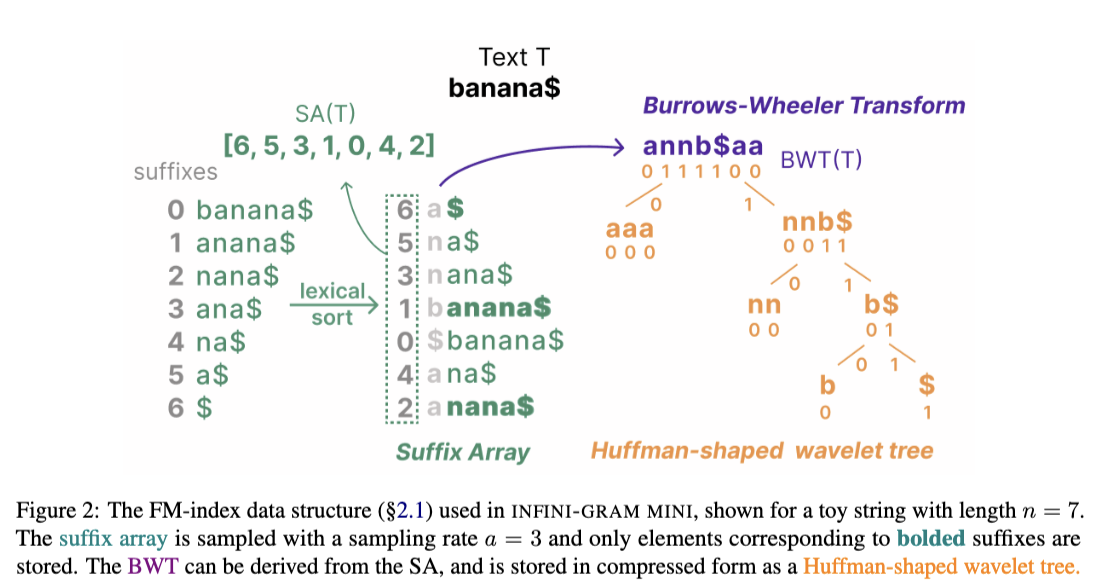
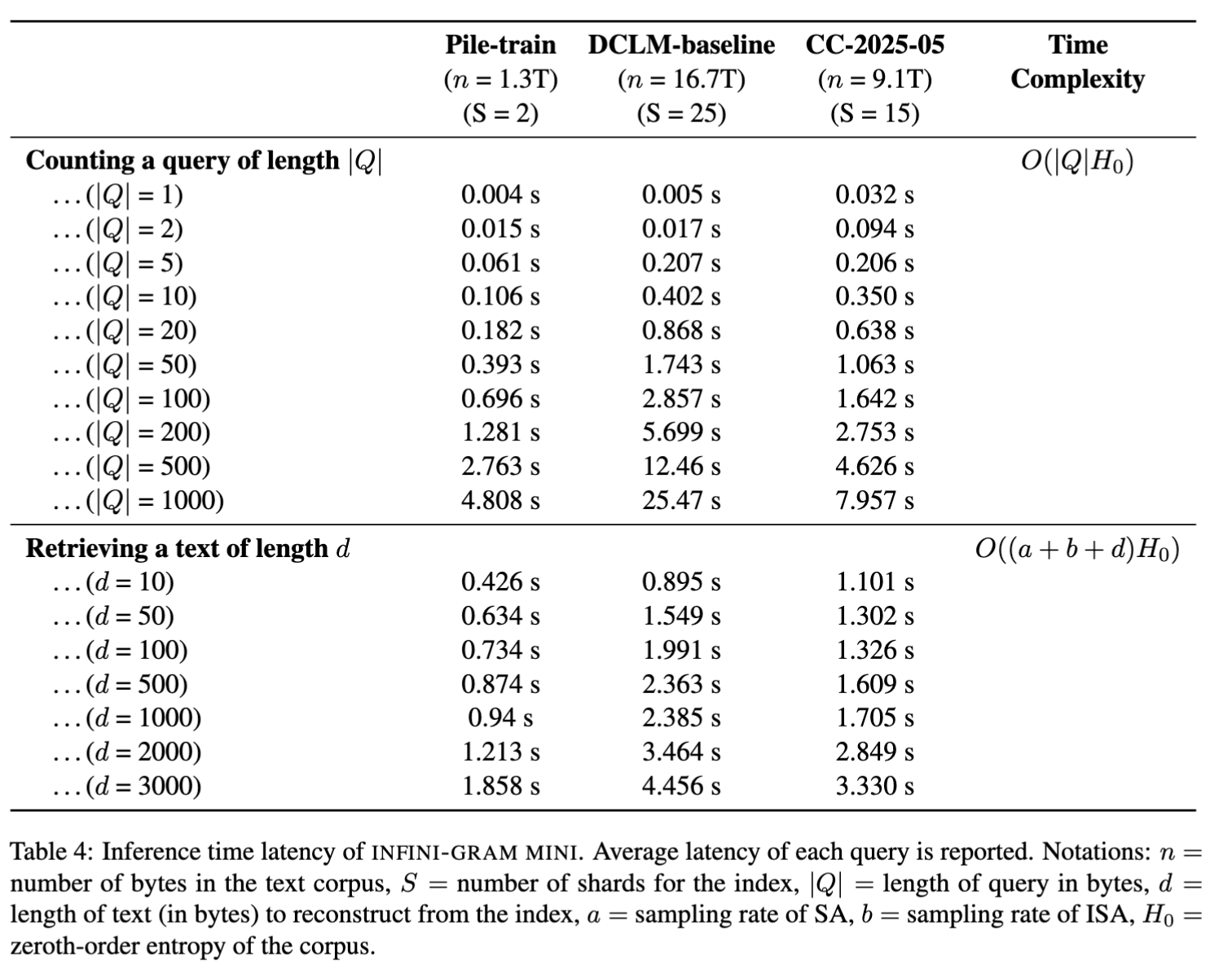
Inference on infini-gram mini is fast. The query latency depends on the size (thus number of shards) of the index. Retrieving a document takes a bit longer, because the index does not store the original text in a contiguous block, and it requires a large number of reads in random addresses when reconstructing character-by-character.
Citation
If you find infini-gram mini useful, please kindly cite our paper:
@misc{xu2025infinigramminiexactngram,
title={Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index},
author={Hao Xu and Jiacheng Liu and Yejin Choi and Noah A. Smith and Hannaneh Hajishirzi},
year={2025},
eprint={2506.12229},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.12229},
}